|
BASIC INSTRUCTIONS
To use the basic functionality of GMoS, simply fill the POSITION box with either a single position (e.g. 3.49) or range of consecutive positions (e.g. 3.49-3.51) from a transmembrane segment, using the Ballesteros-Weinstein numbering scheme.
The output will consist in a list of the residues or sequence motifs that appear at this position (or range of positions) in the Class A sequence alignment, ordered according to their abundance. Clicking on the Optionally, the search can be restricted to a specific residue (e.g. D) or sequence motif (e.g. DRX, where X can be used as a wild card), by filling the SEQUENCE MOTIF box.
In this case, the output will consist in a list of the families that present this residue or sequence motif at this position, ordered and colored according to the conservation within the family. Again, clicking on the In either case, the search can be restricted to a specific SUBSET (i.e. the whole Class A alignment or only human sequences without olfactory and orphan receptors) or FAMILY (i.e. amine, peptide, ... receptors) using the pull-down menus. 
By default, families with no matches in the sequence motif search are not shown in the results. If desired, the whole list of families can be shown by checking the "Show families with 0 matches" checkbox.
For each option, clicking the DETAILED INSTRUCTIONS
The position of the motif in the sequence has to be specified in the Ballesteros-Weinstein numbering scheme [1]. In this numbering method, the position of each residue is described by two numbers: the first (1 to 8) corresponds to the helix in which the residue is located; the second indicates its position relative to the most conserved residue in that helix, arbitrarily assigned to 50. These patterns are easily identifiable on a multiple sequence alignments, and allow an easy comparison among residues in the helical segments of different receptors In bovine rhodopsin, the most conserved residues in each helix are: TM1 Asn55 (1.50) (98%) TM2 Asp83 (2.50) (92%) TM3 Arg135(3.50) (97%) TM4 Trp161(4.50) (96%) TM5 Pro215(5.50) (77%) TM6 Pro267(6.50) (98%) TM7 Pro303(7.50) (96%) hx8 Phe313(8.50) (36%)Thus, for instance, 3.49 corresponds to the residue located immediately before the highly conserved Arg at position 3.50 in the cytoplasmic side of TM3. Obviously, searches are restricted to the positions present in the sequence alignments. Currently, these positions are TM1 1.23 - 1.61 TM2 2.37 - 2.72 TM3 3.23 - 3.63 TM4 4.40 - 4.71 TM5 5.33 - 5.69 TM6 6.28 - 6.61 TM7 7.38 - 7.53 hx8 8.40 - 8.57Note that cytoplasmic helix 8 has been also included in the alignment. In this case, the 8.50 position has been assigned to Phe313 (in rhodopsin numbering), as it is the most conserved position in helix 8 within human Class A GPCRs. Finally, the equivalence between the Ballesteros and other general numbering schemes can be found at this table, created by Elaine C. Meng, at UCSF.
GMoS allows the search of either individual amino acids or sequence motifs of an arbitrary length and complexity. In the latter case, "X" can be used as a wild card. The amino acids must be written in one-letter code, and the field is case-insensitive. For instance, if you are interested in finding conserved sequence motifs starting at the 2.45 position, you could perform the following type of searches: Sequence motif Results
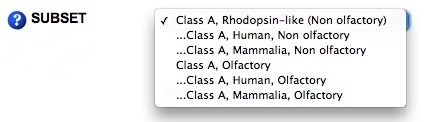
The search can be performed on various alignments, which can be selected through the SUBSET drop-down box. To avoid biasing of results due to the unusual properties of the large olfactory subfamily these databases were separated into all species non-olfactory (1671 sequences, default) and olfactory (540 sequences) class A GPCRs databases (selected in the SUBSET drop-down box). In addition, this SUBSET drop-down box allows to further refine the search to mammalian (1361 sequences) and human (283 sequences) non-olfactory and mammalian (452 sequences) and human (416 sequences) olfactory sequences. A powerful tool of the GMoS set of programs is their capability to perform the statistical analysis for GPCR families and subfamilies. The default is the "Class A, Rhodopsin-like (Non olfactory)" alignment.
By default, searches are performed in the whole alignment. However, they can be restricted to any specific subfamily (for instance, search only within beta-adrenergic receptors) using the FAMILIES drop-down box. The classification is based on ligand type, according to the families listed in the GPCRdb. Clicking on the "-> All" line will revert the search to the whole alignment. References [1] Ballesteros, J. A.; Weinstein, H. Integrated methods for the construction of three dimensional models and computational probing of structure-function relations in G-protein coupled receptors. Methods in Neurosciences 1995, 25, 366-428. |







|